7 Inference for numerical data: >2 samples
7.1 Introduction
In this chapter, we introduce the use of one-way analysis of variance (ANOVA) for hypothesis testing of more than two sample means with normal distributions. ANOVA was first introduced by the statistician R.A. Fisher in 1921 and is now widely applied in the biomedical and other research fields.
ANOVA is a single global test to determine whether the means differ in any groups. In addition, the term “one-way” is used because the participants are separated into groups by one factor (e.g., intervention).
7.2 The basic idea of ANOVA
ANOVA separates the total variability in the data into that which can be attributed to differences between the individuals from different groups (between-group or explained variation), and to the random variation between the individuals within each group (within-group or unexplained variation). Then we can test whether the variability in the data comes mostly from the variability within each group or can truly be attributed to the variability between groups.
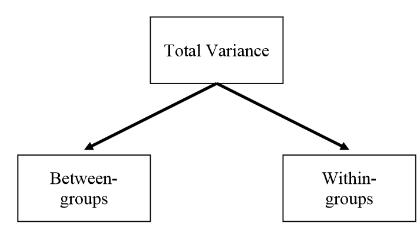
These components of variation are measured using variances, hence the name analysis of variance (ANOVA). Under the null hypothesis “the group means are the same”, the between-group variance will be similar to the within group variance. If, however, there are differences between the groups, then the between-group variance will be larger than the within-group variance. The F-ratio, which is the test statistic for ANOVA, is obtained by dividing between-group variability by within-group variability.
The calculation of the F-ratio involves to calculate the Sum of Squares, SS, the degrees of freedom, df, and finally the variances (Mean Squares, MS). Let’s see each of them more analytically:
7.3 Hypothesis testing of ANOVA
Step 1: State the null hypothesis and alternative hypothesis
\(H_{0}\): all group means are equal (\(μ_{1}=μ_{2}=...=μ_{k}\)).
\(H_{1}\): at least one group mean differs from the others (\(μ_{i} \neq μ_{j}, \ i,j = 1, 2, 3, ...\))
Step 2: Set the level of significance α = 0.05.
Step 3: Identify the appropriate test statistic and check the assumptions. Calculate the test statistic using the data.
Τhe appropriate parametric statistical test, for testing \(H_{0}\), is the ANOVA test. (NOTE: first check for normal distributions and homogeneity of variance). The F-statistic is calculated by creating a ratio of the between-groups variance (Equation 7.8) to the within-groups variance (Equation 7.9):
\[F = \frac{MS_{B}}{MS_{W}} \tag{7.10}\]
This statistic follows an F-distribution with a pair of degrees of freedom \(df_{B} =k−1\) (numerator), \(df_{W} =n−k\) (denominator).
Step 4: Decide whether or not the result is statistically significant.
Based on the calculated F-statistic (Equation 7.10), we have to decide whether to reject or fail to reject the \(H_{0}\). If the computed F-value falls in the rejection region (area of the two red tails), we reject \(H_{0}\).
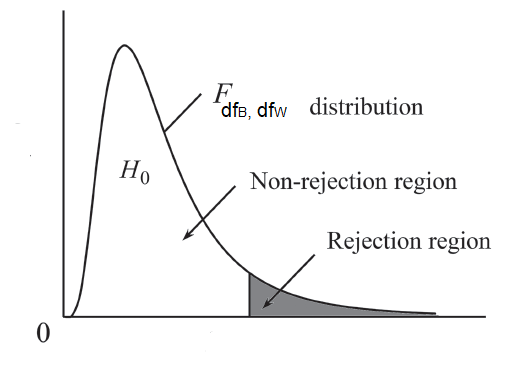
An interesting point about the F-ratio is that because it is the ratio of between variance to within variance, if its value is less than 1 then it must, by definition, represent a non-significant effect.
In practice, we use the p-value (as generated by Jamovi based on the value of the F-statistic) to guide our decision:
- If p − value < 0.05, reject the null hypothesis, \(H_{0}\).
- If p − value ≥ α, do not reject the null hypothesis, \(H_{0}\).
Step 5: Interpretation of the results. If we reject \(H_{0}\) in ANOVA, there is at least one mean that differs from the others. It is often of interest to further examine which of the means are significantly different and which are not. However, it is invalid to employ multiple two independent samples t-test to examine the difference of means for each pair of groups because this will inevitably lead to a rapid increase in the probability of the familywise Type I error rate (FWER). In this case, we can employ a post-hoc procedure (e.g. Tukey test, Games-Howell tets) to compare three or more groups while controlling the probability of making at least one Type I error.